So after coding out the KNN algorithm with Breadth First Search (BFS), I realized how horribly it would scale. But I wasn’t really looking forward to going to back to work on my senior design project just yet so I decided to come up with a new way of doing path planning. First let us partition the space into two distinct graphs, one coming from the starting position and the other from the goal. With this, we can make some optimizations so the algorithm isn’t entirely random, but will be statistically more likely to trend to the other graph. But that partitioning doesn’t help all that much. So I decided to collect the outside nodes of the graph, which are those which have no children (assuming there is a direction from the initial node to the one generated). With those we can determine if we are within epsilon from a given node on the other partition.
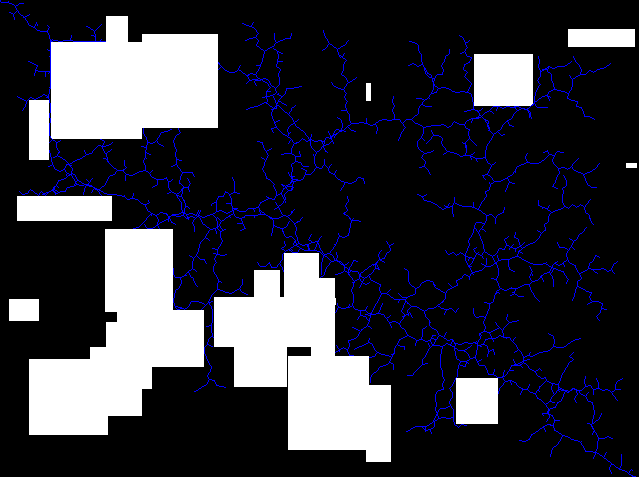
And the corresponding crossovers (Green is the goal graph outer nodes, blue is the starting graph outer nodes and red are the crossovers, where a green node and blue node fall within a neighborhood epsilon).

And another example:

Once we have this, we can generate the possible paths to reach a crossover node for each partition! Green is the path from the start to the crossover point and blue is the path from the crossover point to the goal.
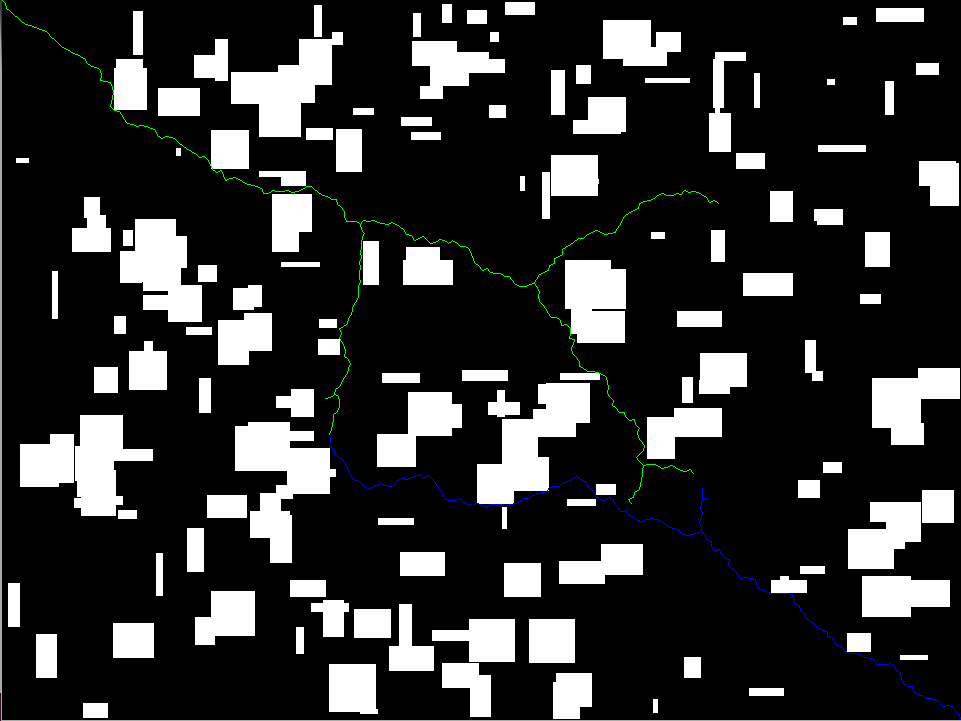


So now we just have to decide on which path to take! We can just sum the costs of each possibility to do this.
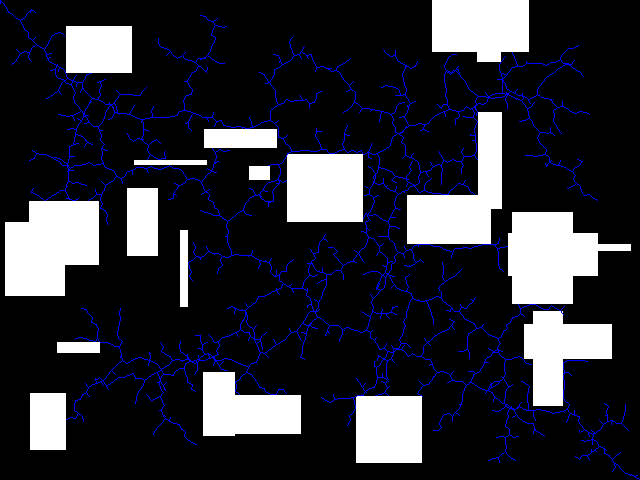
It even works pretty well on very complicated maps!

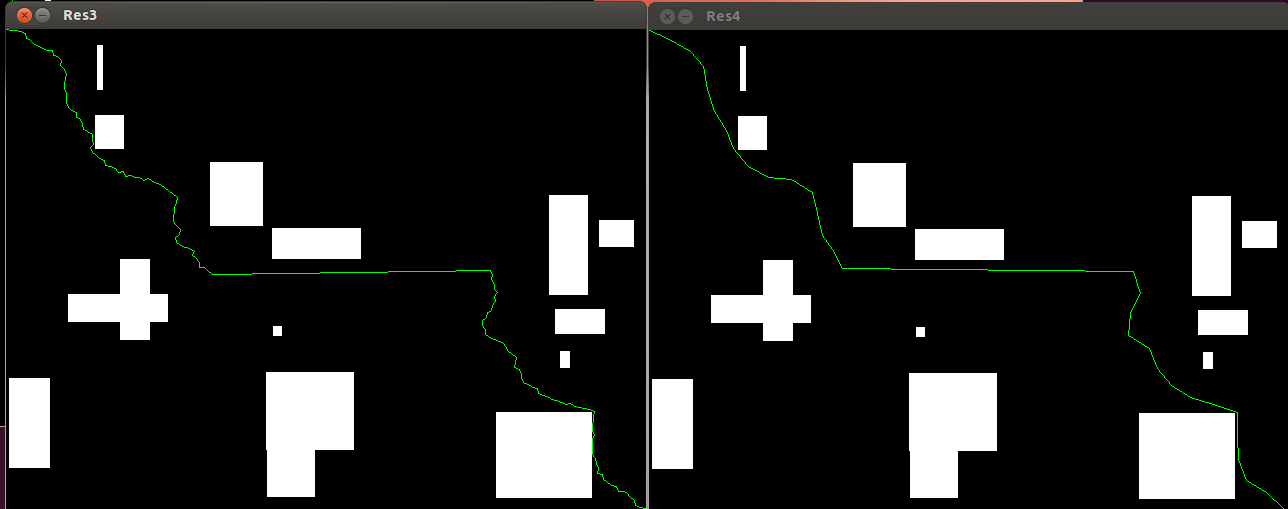
I also attempted to design my own smoothing algorithm, which failed pretty badly, so I just removed some precision and that gives a halfway decent result. I might revisit the problem of smoothing.
The left is unsmoothed and the right is after smoothing.