The goal of this post is to discuss the design a system that accepts an input data stream 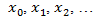 at Port 1 and produces a stream of output data points at Port 2. The output stream should look like:
at Port 1 and produces a stream of output data points at Port 2. The output stream should look like:
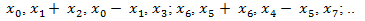
All data is 8 bits wide and uses 8-bit 2’s complement arithmetic. On every clock, one data sample enters and one leaves the system.
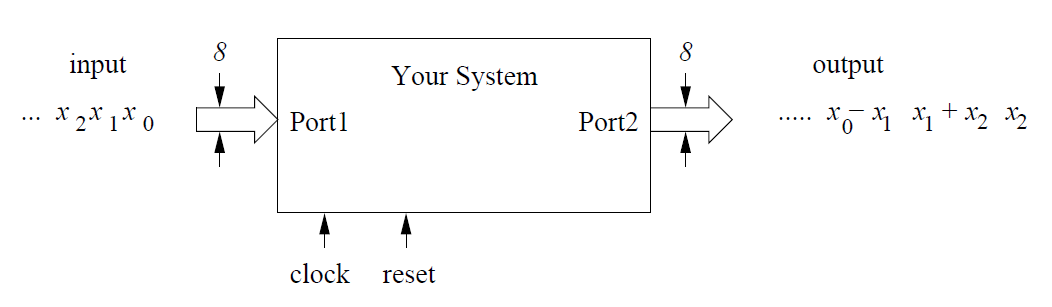
Overview of the System Requirements
Abstractly speaking, system described in the problem statement, accepts data in one order, and mixes linear combinations of the inputs in different, predefined orders. As with any digital system, it is important to separate architecture from control. With regards to the architectural design of this system, the architecture chosen with regards to a simple data shuffle layout of registers, along with an adder. Constraints are placed on the design with regards to throughput and low power.
Based on the specification and constraints, it is clear that using a shift arrangement of registers is not optimal, thus an optimal shuffle architecture is utilized. Since only two operands are applied to the adder at a time, Carry Propagation Adder (CPA) and Group Carry Lookahead Adder (GCLA) are among the possible choices to build a successful architecture. The CPA scales as (2n+4)Δ =O(n), whereas the GCLA scales as O(nlog(n)). Since an 8-bit adder is required, the CPA will need 20Δ, and the GCLA will need 12Δ to complete. A CPA was chosen since the amount of additional hardware required for the GCLA was too much of a tradeoff for the 8Δ increase in speed.
With regards to the control, a periodic control implementation was used centered on a modulo-12 counter. For simplicity in the control logic, this counter was then fed to a decoder which took the 4-bit counter and expanded it to a 16-bit wire. Each bit on this wire represented a state, from the modulo-12 counter. Once the current state was generated, control logic generated the signals for the register control, multiplexers and the add-subtract signal. These signals were then fed into the architecture. Additionally, a done flag was added that went high on the clock cycle of the last output.
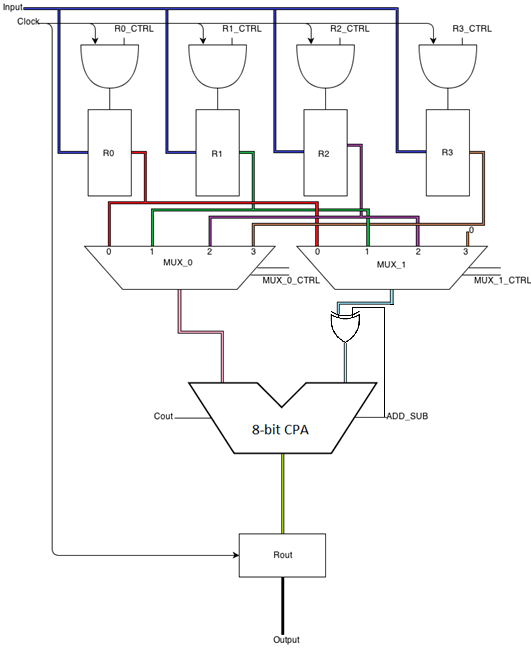
Architecture / Datapath
The system can easily be modeled based on the input into the system on a given clock cycle and the desired output. This is the first step in designing the control.

From the problem statement, and design approach, a data shuffling architecture will be used. A minimum of 4 8-bit registers are required for storing the data in this problem. From this a new table can be generated, showing how data will be stored in each register.i
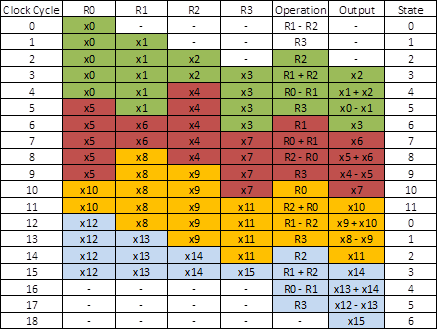
From this table, it is obvious that there are 12 possible states the system can be in, and therefore a modulo-12 counter is required. With the above states, the signals for the multiplexers can also be determined.
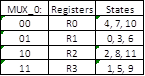
Since R3 is not used in MUX_1, it can be replaced with 0’s to enable a single register’s value to be outputted. Only zeros should be produced from MUX_1 when in states 1, 2, 5, 6, 9, and 10. When generating the control signal for the adder using the same concepts above can be applied to produce a signal that is zero when the operands should be added and one when they should be subtracted. The states when addition is required are 3, 7, and 11. The states involving subtraction are 0, 4, and 8. The remaining states where no operation is required are states 1, 2, 5, 6, 9, and 10. Since no operation can be thought of as adding 0 to the current value, these states were lumped into the zero condition on the adder control signal.
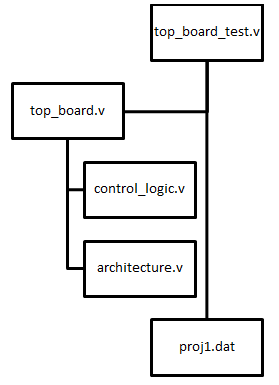
The system was implemented using the following hierarchy:
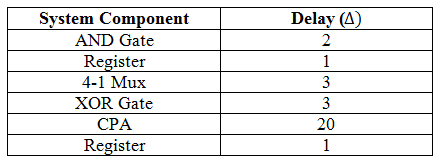
Based on the architecture, the system speed was 30Δ. This can be determined by finding the critical path, and then the speed of components along that particular critical path. The critical path consisted of the AND gate which was used to control the clocking of the registers to hold the input, these registers, though MUX_1, the XOR gate and finally through the adder and into the final register. This produces delays of:
The simulation results are shown below.