The goal of this post is to design an 8 bit processor with the following specifications:
- The processor has seven 8-bit registers A, B, C, D, E, H and L.
- The processor begins by executing instruction at address 0.
- It connects with an external memory containing 32 8-bit words. The memory has a tristate output with active low signals rd and wr.
- It has instructions MOV, MVI, LDA, STA, ADD, SUB NOP and HLT. It can also add or subtract data directly from memory.
- The op-codes for the instructions are defined as follows. The registers A, B, C, D, E, H and L are coded as 111, 000, 001, 010, 011, 100 and 101 respectively. The letter M always refers to the contents of the memory address in the least significant 5 bits of the L register. The opcodes may then be described as follows:

The processor specified in the prior section can easily be realized into hardware through the use of a typical processor architecture. Abstractly speaking, the architecture can be divided into an Arithmetic Logic Unit (ALU), a collection of registers, memory for storing code and data, and finally a program counter for tracking which memory address’s contents should be fetched to be placed into the instruction register. As this design was based on Intel 8085, 7 8 bit registers were used, which interact over the bus. With regards to control, the design was realized through the use of step control.
The first instruction to consider is the simplest. NOP or No OPeration involves doing nothing. When the NOP instruction is fetched into the instruction register the step counter remains at zero. This causes the program counter to increment, putting the next instruction onto the bus, which is then loaded into the instruction register.
If the HLT instruction is encountered, the processor stops, until it receives a reset signal. In this case, instructions must no longer be read, so the step counter simply increments by one, then remains in this state permanently.
In the specifications, three different MOV instructions are specified. The first handles moving data between registers, while the other two move data between registers and memory or vice versa. When MOV r1 r2 is loaded into the instruction register, the tristate controlling r2’s presence on the bus is activated, thus putting r2 onto the bus. Then r1 is clocked, so that what was on the bus now is the value of r1. The second type of MOV is MOV M, r, where the contents of r are copied into the memory location specified by bits 4 through 0 of register L. The write signal must go low as both read and write are active low. Furthermore, the read signal must go high. In this case, the contents of r are placed onto the bus by activating r’s tristate. While this occurs, in the control logic, the multiplexer controlling the address passed into memory, changes from the program counter to L register. The third and final type of MOV is MOV r, M, which takes the contents of the memory address specified in register L and places them into r. To do this, the read wire is set low, and the address is changed from the contents of the program counter to the contents of register L. This will put the contents of that location onto the bus, so once r is clocked, the contents will have been successfully moved. This set of instructions only consumes one clock cycle.
The next set of instructions specified in the designed to deal with arithmetic operations on the processor, which consist of addition and subtraction. The only difference between these two instructions is that the second operand must be the result of an exclusive-or with a constant 1, and the carry in will be set to 1, in order to perform subtraction. Within both addition and subtraction, either the operation is performed on register A and a register r or instead on register A and the memory location specified in the 4 least significant bits of register L. Both of these operations behave very similarly. If the value must be fetched out of memory, it is done using the technique described above. From the op code, it can be determined whether to set the subtract flag to 1 or to 0. With this, the Carry Propagation Adder (CPA) and the XOR gate can perform the correct operation. As this occurs, the multiplexer controlling the input into register A, must be changed from the bus to the sum from the CPA. After the CPA has finished its computation, register A can be clocked to move the result back into A.
The next two instructions of interest are LDA and STA. LDA loads the value from the specified memory address into A. This results in taking the op code and using part of it as an address for the specified value. From here, register A can be clocked to successfully load the value. STA takes the value currently in register A and places it into the specified register. Since A must be written to memory, the write signal must be set low, and the read must be set high. Then using the same method of splitting the address off of the instruction register previously described, the address that A should be stored to can be inputted to memory. Once this is done, the write line and read line should be returned to their default states. Both of these instructions consume a signal clock cycle.
The final instruction that this processor supports is MVI. One of the challenges with MVI is that the program counter needs to be incremented while executing the instruction, since it takes up multiple bytes. Executing this instruction takes up two clock cycles. However it is very similar to MOV r, M, except with more flexibility as to the register the user wishes to load the value into.
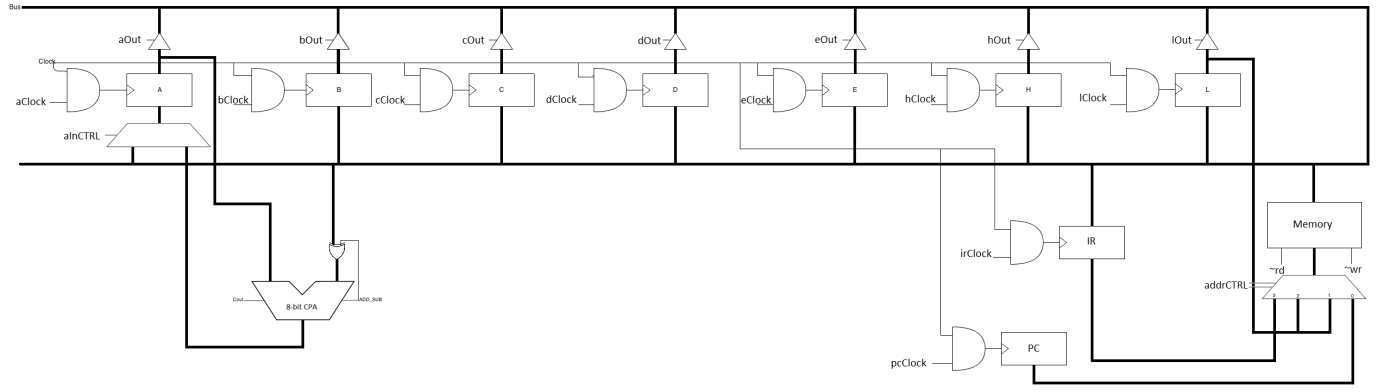
Processor Architecture
The above architecture was used to enable the design of the processor. Not shown: three decoders that process the instruction register and break it up into different commands for each register. This is part of the control logic.
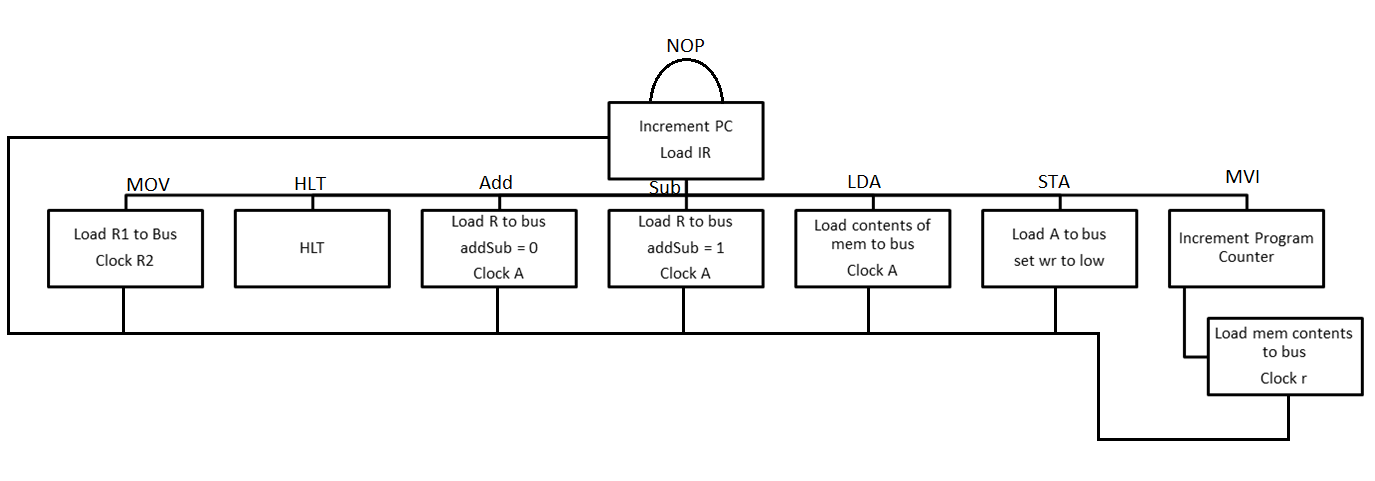
Processor Control- Step Control
The step control logic above was implemented based. As there are a total of 3 steps, a 2 bit counter was sufficient to act as the step counter. All instructions loop back to the first state, except in the event of a halt, which stays permanently in that state. MVI was the only instruction that took more than 1 clock cycle to execute.
When considering design enhancements for speed, the most important measure is the critical path. In this design, the critical path is when an Add or Subtract instruction is executed. This is because these instructions must go through the adder. The critical path is:
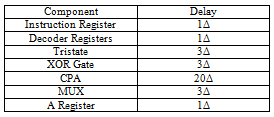
Therefore, the critical path is 32Δ. One element along the critical path that can be easily improved, is the CPA. If switched with a Group Carry Lookahead Adder (GCLA), 8Δ could be shaved off of the critical path, reducing it to 24Δ. Another critical path exists with the MVI instruction since it takes an extra clock cycle, compared to the rest of the instruction. However, there are no feasible enhancements to improve that critical path.
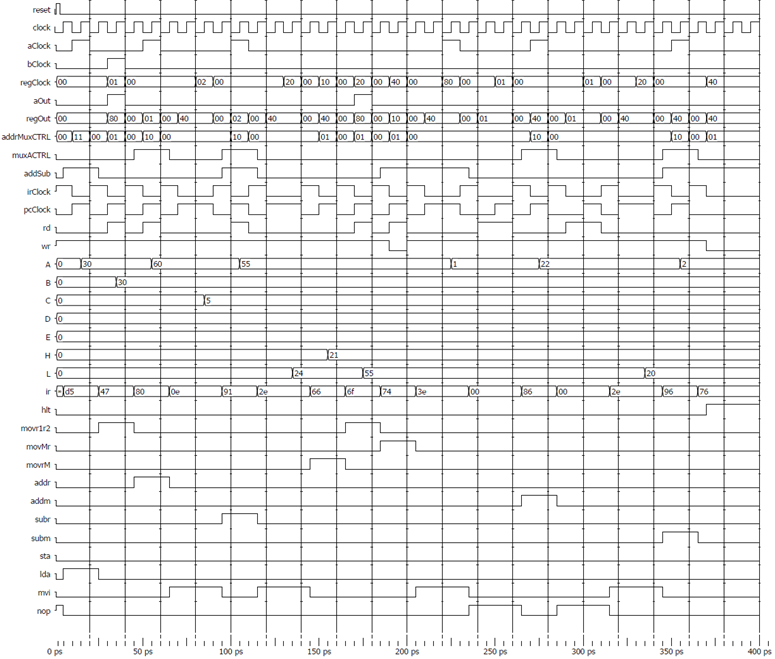
Below is the simulation of the design: