Due to the predictive twitter project, I now have far too many tweets on my computer. Instead of letting them just take up disk space, I decided to perform sentiment analysis on the tweets. The goal of sentiment analysis is to extract subjective information from text. In this case I want to find the polarity of each tweet. Polarity is simply a number where its sign determines whether the text is positive or negative. The magnitude determines how positive or negative a piece of text is. I love Alchemy for NLP however they limit you to 1,000 API calls a day and I needed to process 1 million tweets. Well that approach wasn't going to work. So I started rolling my own! It kind of worked, but wasn't as good as I would have liked. I probably could have improved it using Amazon's Mechanical Turk, and spending the rest of the night improving the code, but for starters, it was slow, and I have some other things I need to start working on. After some research, I came across textblob, which is based on Natural Language Toolkit (NLKT). I ran some tests and it produced pretty good results. For the tweets, I had a lot of zero sentiment results but I can't complain since it was doing much better than my homemade one.
Had I known I was going to start looking into sentiments, it would have been nice to have logged the particular trend I was monitoring, or even timestamped the tweet. But I wasn't thinking about that yesterday. So basically I have 1 million pieces of text to work with, and no context. Even though I was already off to a bad start, I decided it couldn't get any worse, so I started the processing the data. I had all my sentiments after waiting a bit, and working on my homework. However I didn't know exactly how to visualize the sentiments just yet so I decided to log them to a file.
So after I decide how to process them, I decided to load them back into memory which is where I made my next mistake. I tried to read the file, but opened it with the write option... There goes all the results. Another round of processing and the data is back, so maybe it wasn't the biggest deal. Out of curiosity (or stupidity), I decided to just plot all the points using Matplotlib, and managed to crash a few programs, and not to mention the results look awful!
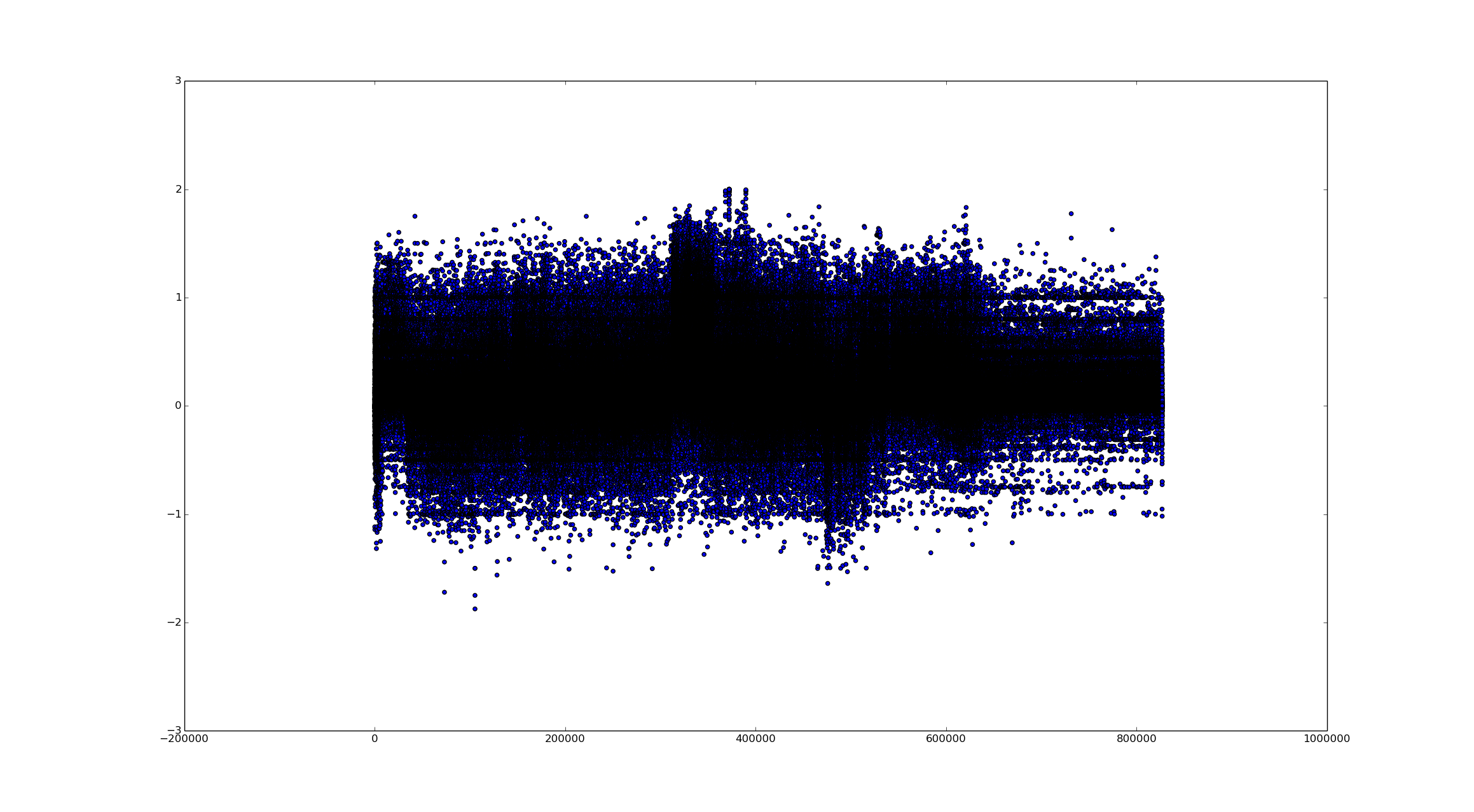
After a bit of thinking, I decided to just downsample the results at the end using an average over a fixed interval. I also threw in a custom decay filter using a decay of 2 and 50 points of resolution.
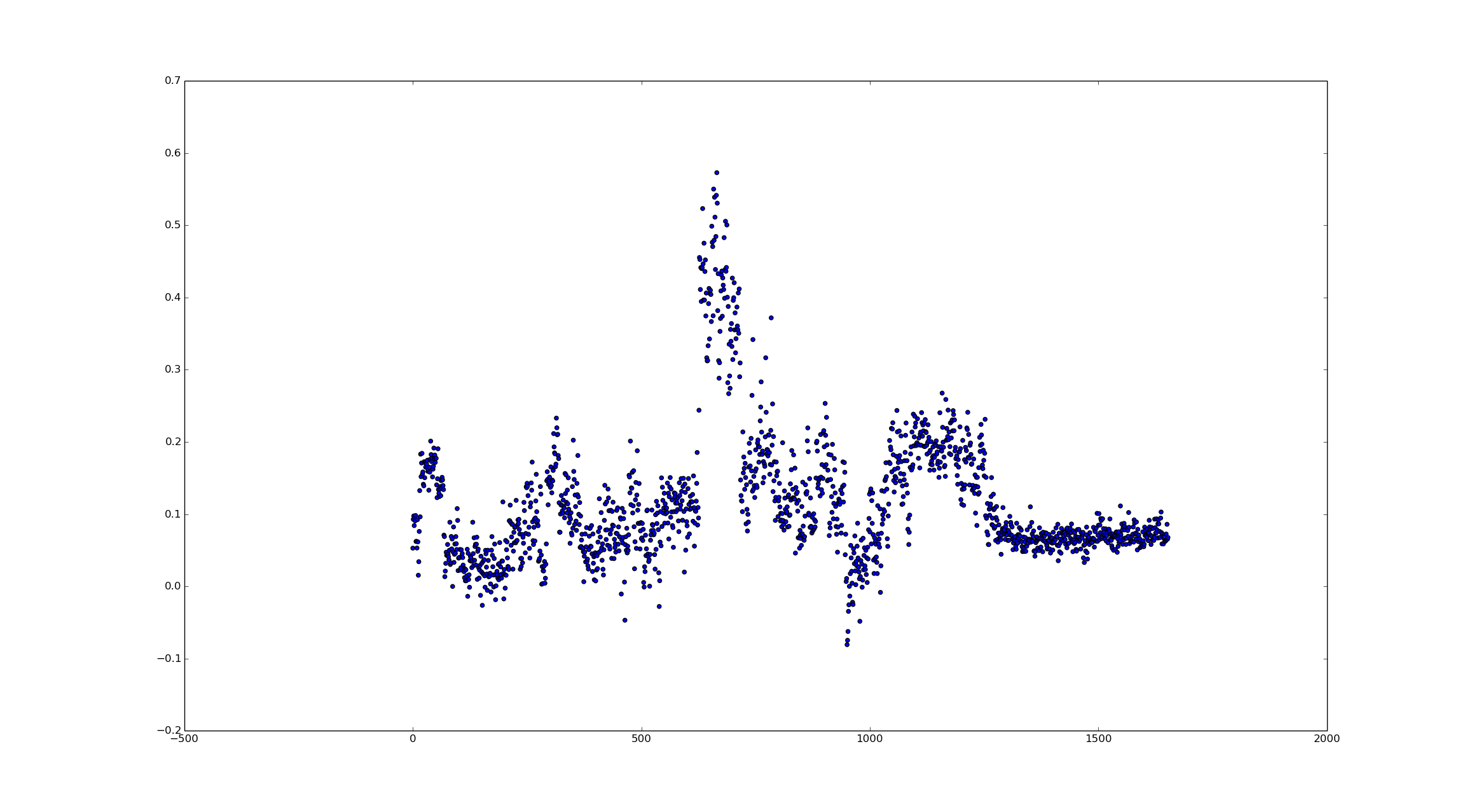
But that looks really sparse. I overcompensated on the downsampling, but after reducing the amount of downsampling I got some interesting results. I also increased the smoothing filter to 100 points.
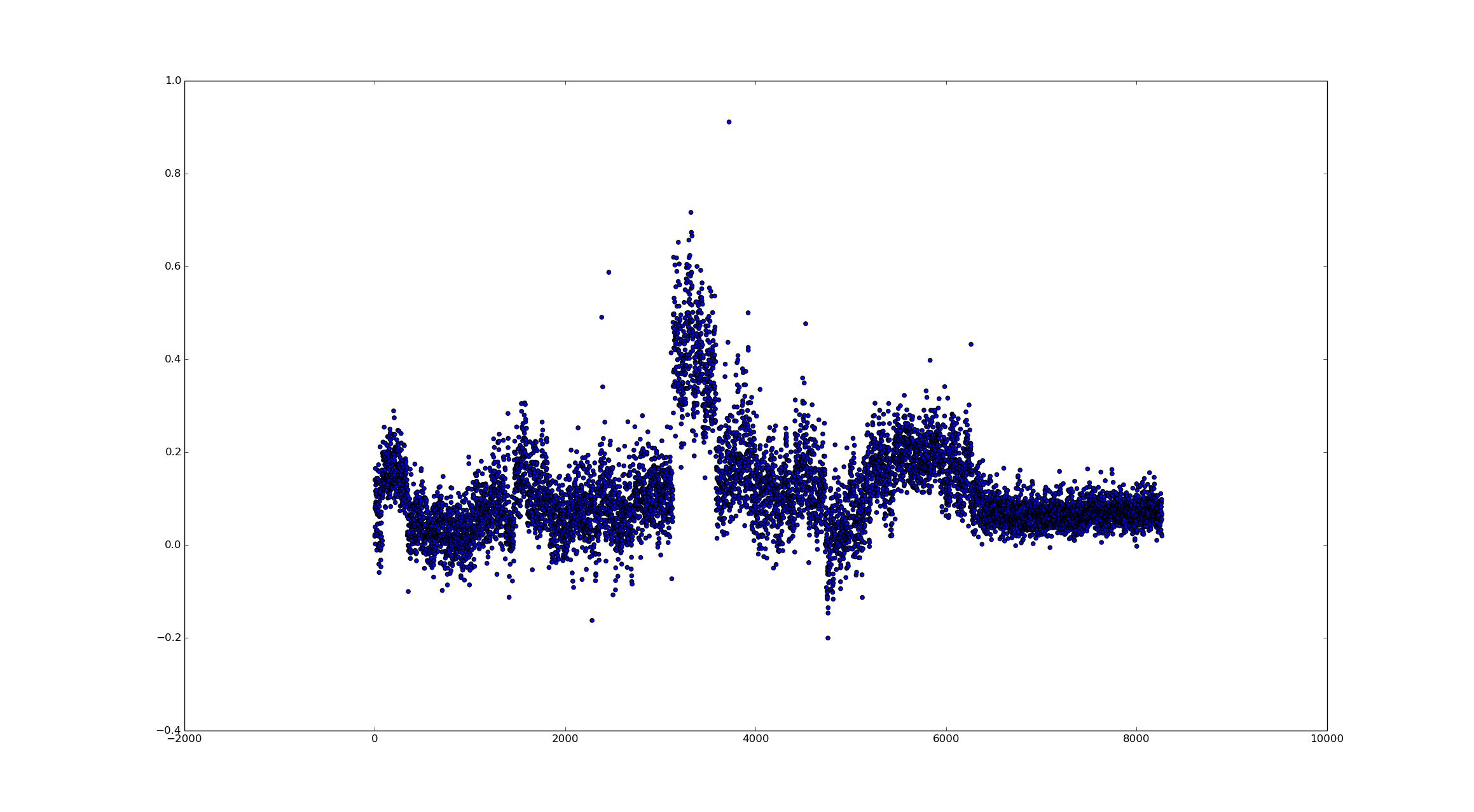
Increasing the filter shouldn't really have any noticeable effect on the data, but to verify I decided to increase the smoothing filter to 500 points.
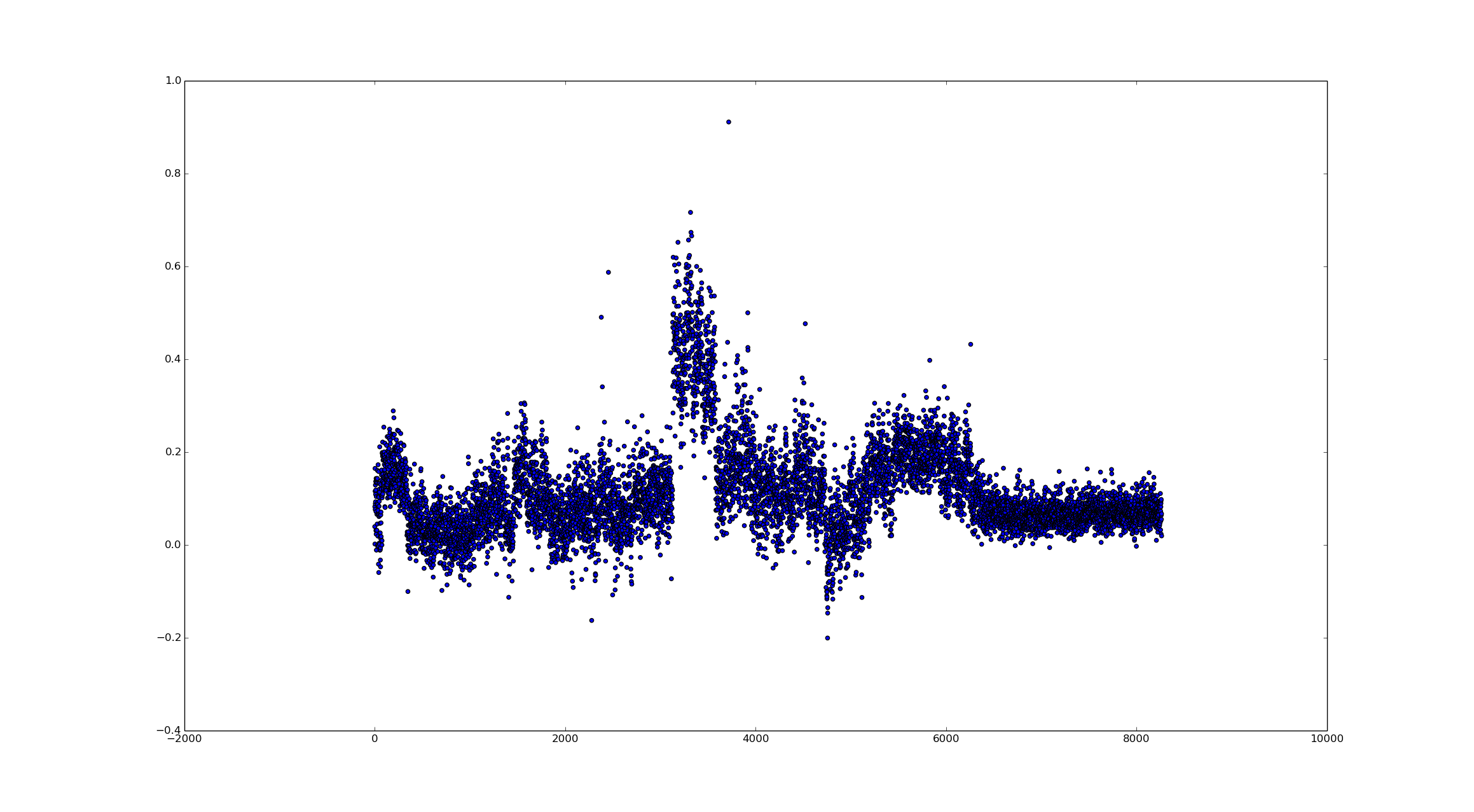
Now let's decrease the downsampling factor by half. This gives us twice as many data points.
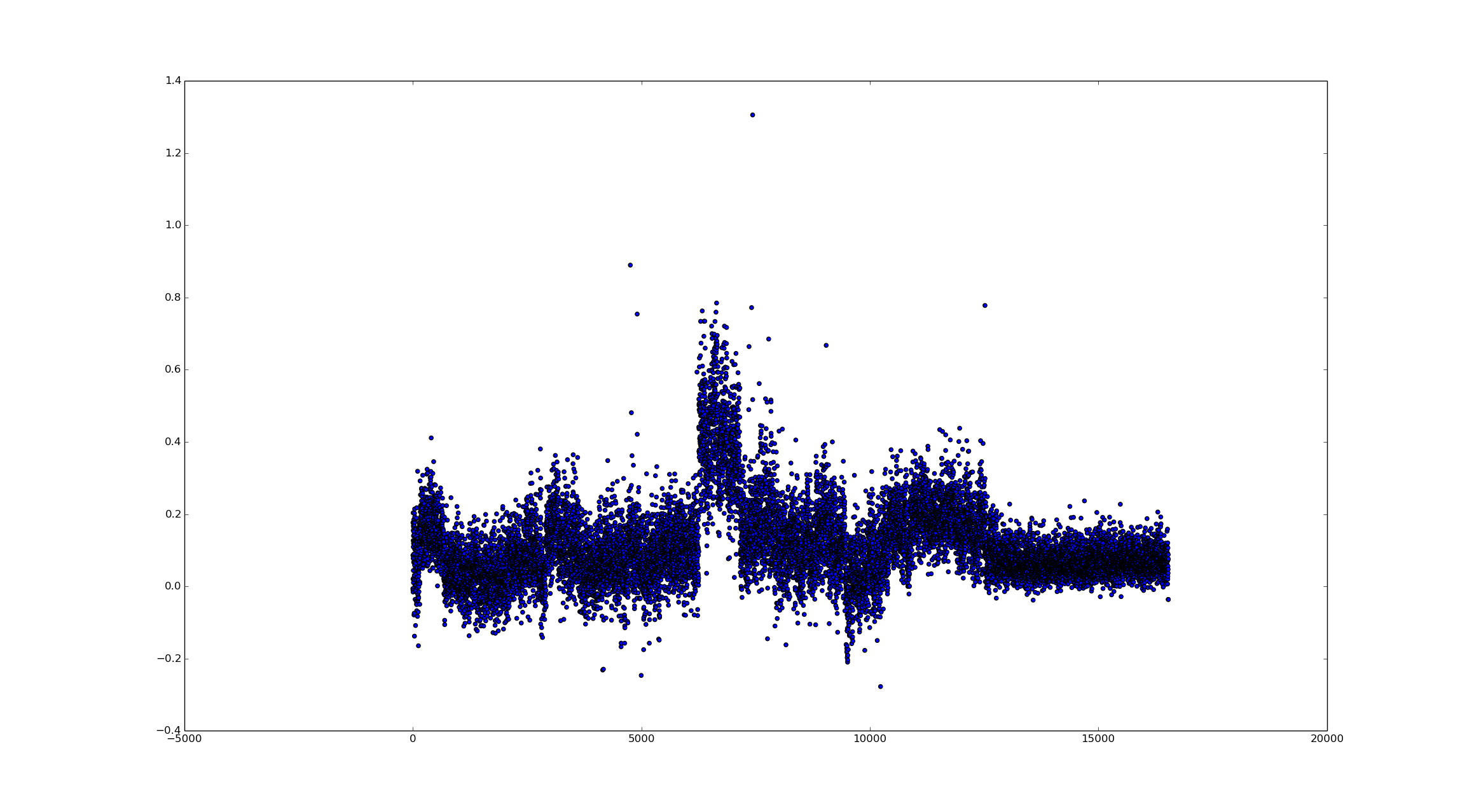
Out of curiosity, I wanted to see how much the smoothing filter actually did. So I decided to run it with a size of 1. This effectively removes all effects it has.
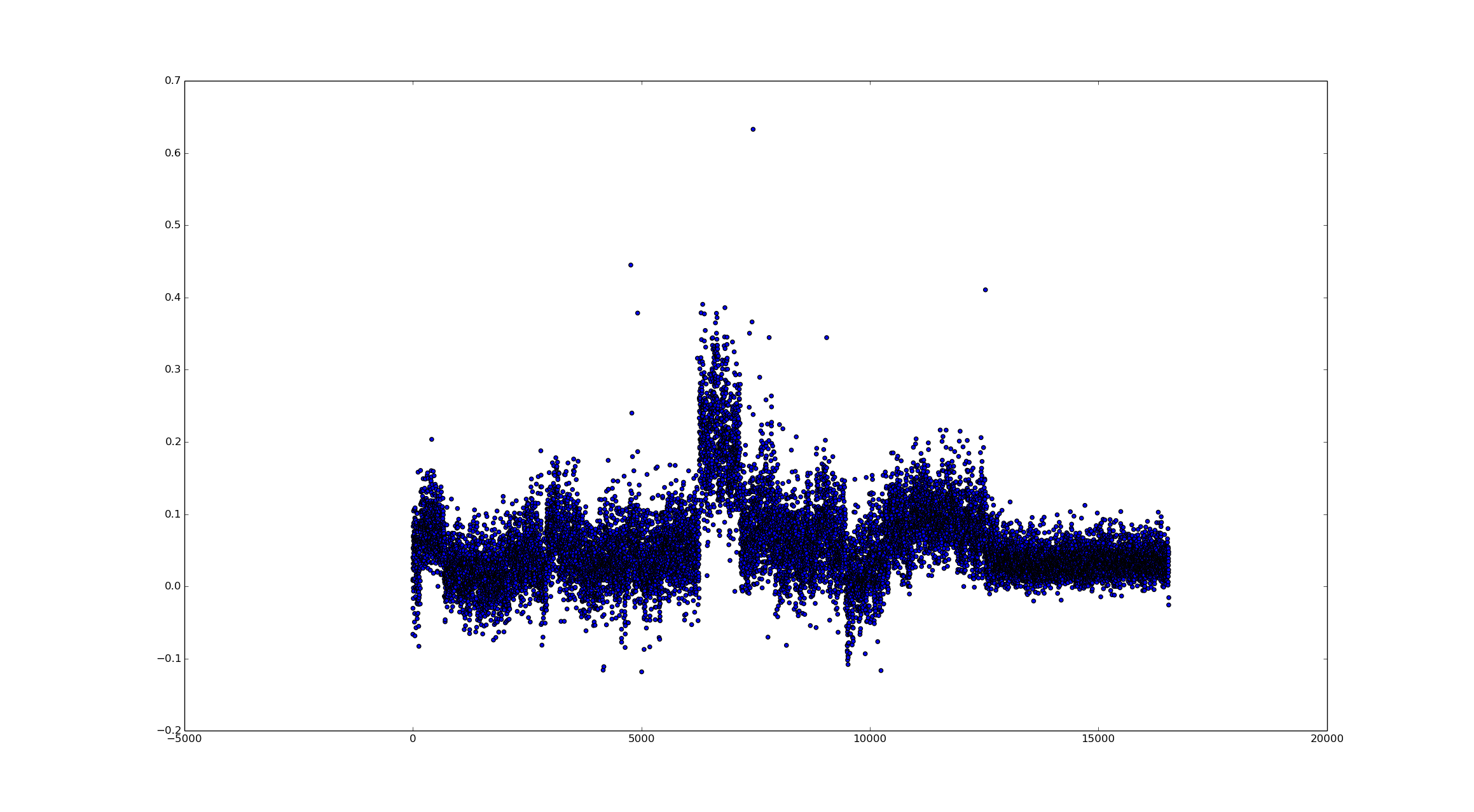
From the data, we can clearly see different sentiments which I assume can be directly tied to a trend on Twitter. I am really curious as to what the large positive spike was related to. So some events that were covered in this data were the Monroeville Mall Shooting, the Brian Williams Scandal, and Bruce Jenner involvement in a fatal car crash. Towards the end of the collection was the #askNick trend which was mostly questions. I hope to revisit this and maybe make the plot interactive using D3.js or some other visualization tool and tie in the timestamps and trends at that moment.